




INTRODUCTION
MongoDB is the most popular NoSQL(Not only SQL) Database and open-source document-based database. MongoDB is used for high-volume data storage, helping organizations store large amounts of data while still performing rapidly.
MongoDB is a document-based database means that it stores the documents containing the data that the user wants to store in the MongoDB database. These documents are composed of field and value pairs. These documents are similar to Javascript Object Notation(JSON) but it uses a variant called Binary JSON(BSON) because BSON is efficient and supports a wide range of data types compared to JSON.
There are ODM (Object data modelling) libraries like Mongoose are helpful for basic queries, but for complex data, only depending on them might slow down the database. That's where the aggregation pipeline in MongoDB comes in. It is a framework that helps write more efficient queries, to handle complex data easily and effectively.
OVERVIEW OF MONGO DB AGGREGATION PIPELINE
what is MongoDB Aggregation Pipeline
The MongoDB aggregation pipeline is a powerful framework for processing and transforming data within MongoDB. An aggregation pipeline consists of one or more stages that process documents. At each stage the operation is applied to the data and the output of this data is input data for the next stage. These stages can perform various tasks such as filtering documents, grouping and summarizing data, transforming data and joining data from multiple collections
Let me explain to you with a simple example imagine you are planning a road trip. It includes various steps or stages like planning the route and stops to reach your destination. Each step is like input for the next step if this is done then do this like in a road trip first plan the route, choose the rest stops, refueling, grab the snacks and eventually arriving at your destination. Just as each step in the journey contributes to reaching your destination smoothly, each stage in the aggregation pipeline contributes to efficiently processing and transforming your data.
HOW IT WORKS:
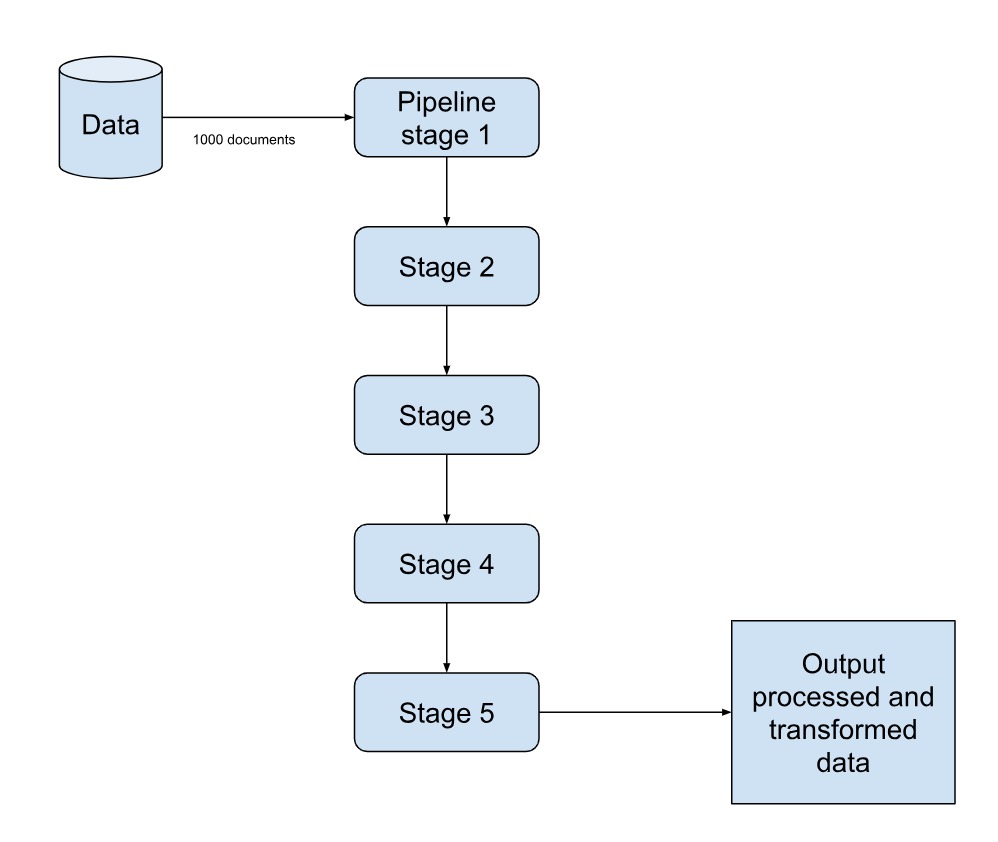
The picture shows how the aggregation pipeline works. It's like a series of steps to change data until we get the desired result (aggregated data). Usually, we start with one collection of data or more, but we can add more collections later to make the results better.
STAGES OF MONGODB AGGREGATION PIPELINE
The previous section has given you knowledge about how the mongoDB pipeline works. In this section, I will explain some MongoDB stages.
Pipeline is nothing about the array of different stages like this
[
{
this is first stage...
},
{
this is second stage...
},
{...},{...},{...}
]
you can write as many as you want pipelines one after another and you can also write nested pipeline.
Aggregation Pipeline Stages :
- $match: This is the most common stage in the pipeline and it is usually used in the first stage of the pipeline. This stage filters the document in the collection on specific criteria just like you are giving a condition and the database retrieves documents on the condition. For example, in the library database, you have two collections called Authors and Books and if you want a book with a specified title you can use the match stage which will return the document with the matched title.
this is sample data that I am using throughout this article :
- books collection:
[
{
"_id": 1,
"title": "Pride and Prejudice",
"authorId": 100
},
{
"_id": 2,
"title": "Emma",
"authorId": 101
},
{
"_id": 3,
"title": "The Adventures of Tom Sawyer",
"authorId": 102
},
{
"_id": 4,
"title": "Harry Potter and the Philosopher's Stone",
"authorId": 102
},
{
"_id": 5,
"title": "Harry Potter and the Chamber of Secrets",
"authorId": 102
}
]
2. author collection :
[
{
"_id": 100,
"name": "Jane Austen",
"birthYear": 1775
},
{
"_id": 101,
"name": "Mark Twain",
"birthYear": 1835
},
{
"_id": 102,
"name": "J.K. Rowling",
"birthYear": 1965
}
]
This is a simple example of the $match stage:

- $lookup: This is usually the second stage in the pipeline. This stage performs a left join to the collection in the same database to filter in documents from the joined collection for processing. This stage enriches the documents in the current collection with information from documents in the foreign collection based on a specified condition or criteria.
This stage has 4 parameters :
from: Specifies the name of the foreign collection from which to retrieve documents.localField: Specifies the field in the current (local) collection that will be used to match documents in the foreign collection.foreignField: Specifies the field in the foreign collection that will be used to match documents in the local collection.as: Specifies the name of the output array field where the joined documents will be stored.
In this example I am applying the lookup stage on book collection with another collection of authors:
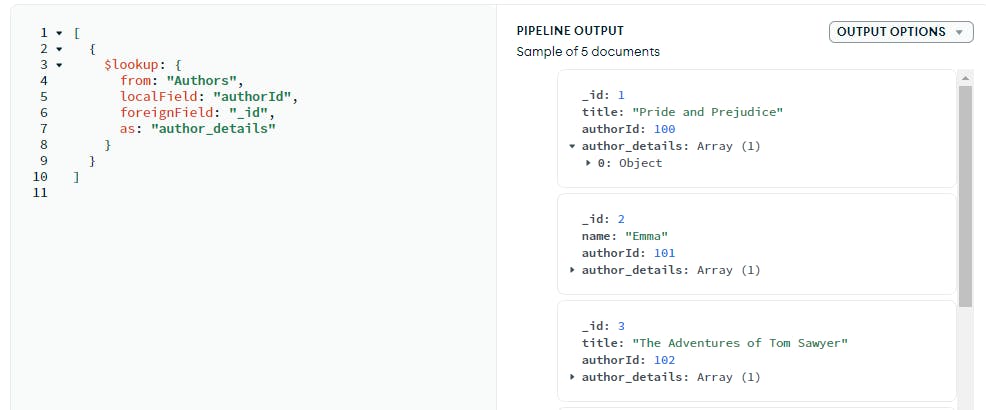
as you can see in the above image the foreign collection is authors and the foreign field is _id for join operation.
this lookup stage will return the array this array field contains the matching document from the joined collection. In this example, The joined documents will be stored in an array field called "author_details" in the output documents.

in this image, you can clearly see that the details about authors are joined to books respectively.
- lookup and match: you can write as many pipelines as you want if you want to filter out some documents with this joined collection you can do it using the match stage. You can use this stage after the lookup and for the match stage, this data is input as I have explained before for the next stage the input data is the previous stage's output.
In this example, I have used the match stage on the lookup stage.

The expression "author_details.name": "J.K. Rowling" specifies the condition for matching documents. It filters the documents where the name of the author, extracted from the "author_details" array field, equals "J.K. Rowling".
- $addFields: The addFields is a powerful operator in the MongoDB pipeline. It allows you to add new fields to the documents in this aggregation pipeline. it does not modify the existing document instead it it creates new fields to overwrite existing fields with new values.

In the provided example, the $addFields stage is used to create a new field named "author_details" in the output documents. The value of this new field is derived from the existing "author_details" array field that was created in the previous $lookup stage. Since the author_details is a derived field make sure you use the "$" sign before its name.
In the author details I have used the $first operator, which is used to extract the first element of the array in this example it will extract the first element of the author_details array and this array comes from the lookup stage that I mentioned above that the lookup stage returns the array of matching documents.
By returning the first element of the array and converting it into a single object, frontend developers can easily access the values using dot(.) notation, simplifying their workflow. This approach reduces the complexity of handling arrays in the frontend code, as developers don't need to iterate through arrays or handle edge cases where the array might be empty or contain multiple elements.
If you decide not to return the first element, get ready to watch your front-end developer navigate through arrays like a pro. It's your call !!
- $arrayElemAt: There is another approach for returning the first element of the array called the
$arrayElemAtoperator. This operator allows you to specify the index of the element you want to retrieve. For example, to extract the first element of the array, you can simply specify the index 0.
- $arrayElemAt: There is another approach for returning the first element of the array called the

Make sure to use indices within the bounds of the array to avoid errors.
- $skip: The skip operator is used in MongoDB's aggregation pipeline to skip a specified number of documents from the beginning of the input. It allows you to skip over a certain number of documents in the pipeline output.
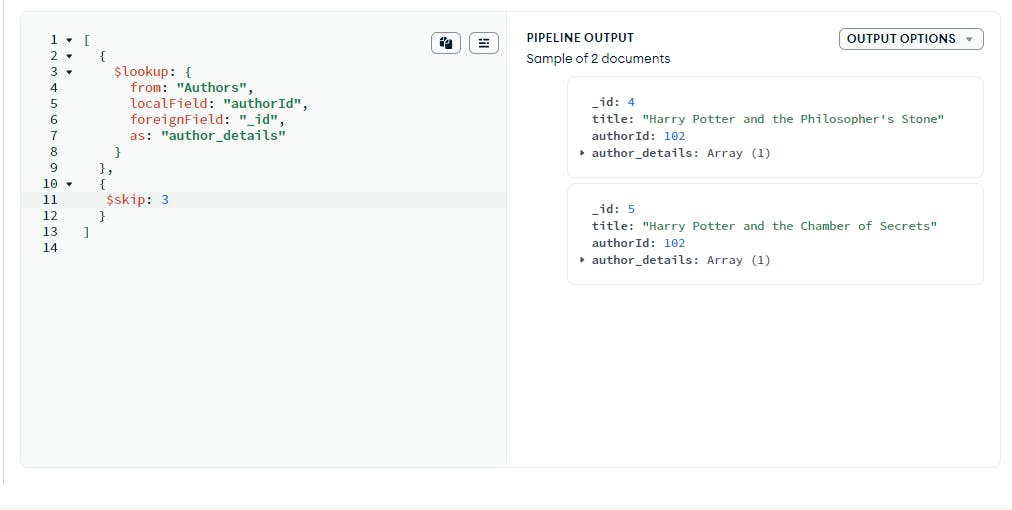
In this example, I have used the skip operation to skip the first 3 documents retrieved from the book collection. The number 3 indicates the number of documents I want to skip from the beginning.
$skip is mostly used when you need to exclude the number of initial documents from the aggregation result, such as when you want to paginate results or ignore irrelevant data.
$limit: The
$limitoperator in the MongoDB aggregation pipeline is used to restrict the number of documents that are passed to the next stage of the pipeline. It allows you to limit the size of the result size of the result set returned by the aggregation.
In this example, I have applied a limit operator on the books collection since the limit is 1 only the first document retrieved from the books collection will be included in the aggregation result.
This $limit operator is commonly used when you want to restrict a number of documents returned by the aggregation pipeline, especially when dealing with large datasets or when you need a subset of the data.
In this article, you learned the fundamentals of the MongoDB Aggregation Pipeline Framework. You learned about its importance, most-used stages, and how it is used in handling relationships between collections.
CONCLUSION
Congratulations on getting this far, you just took the first step in mastering the MongoDB aggregation pipeline. There is a saying that “Practice makes perfect” and There is always more and there is no ending in learning. There are many more operators and more about MongoDB Aggregation pipeline you can explore it on your own.Good luck for this journey.